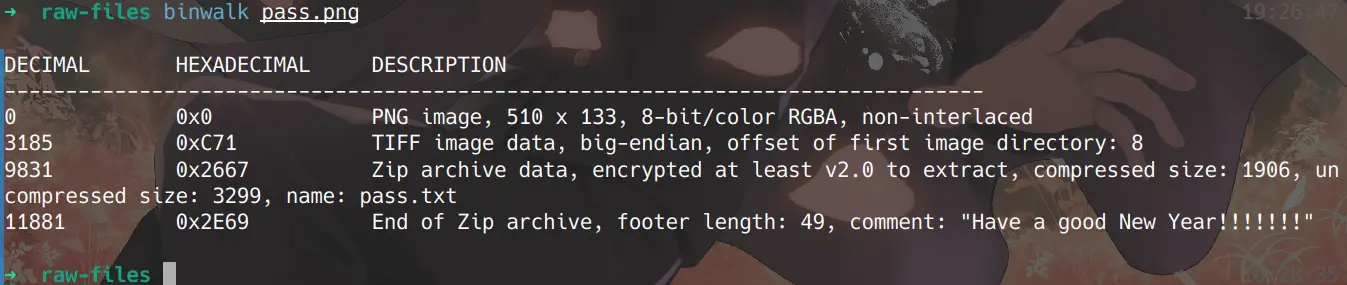
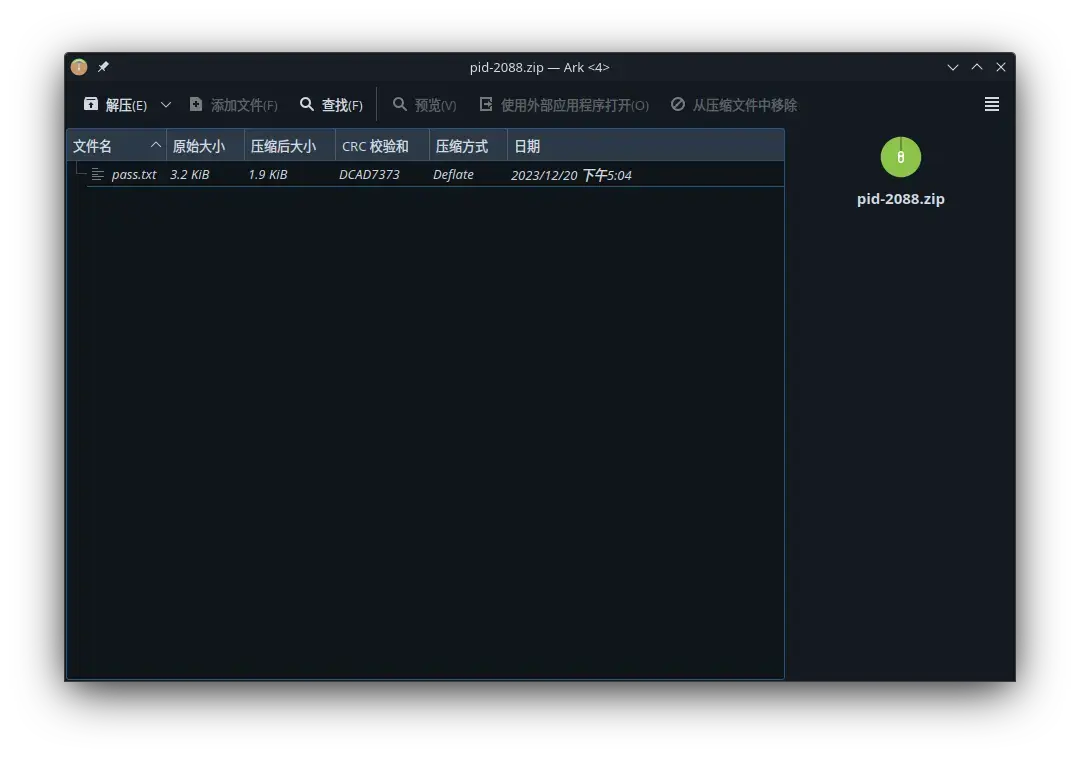
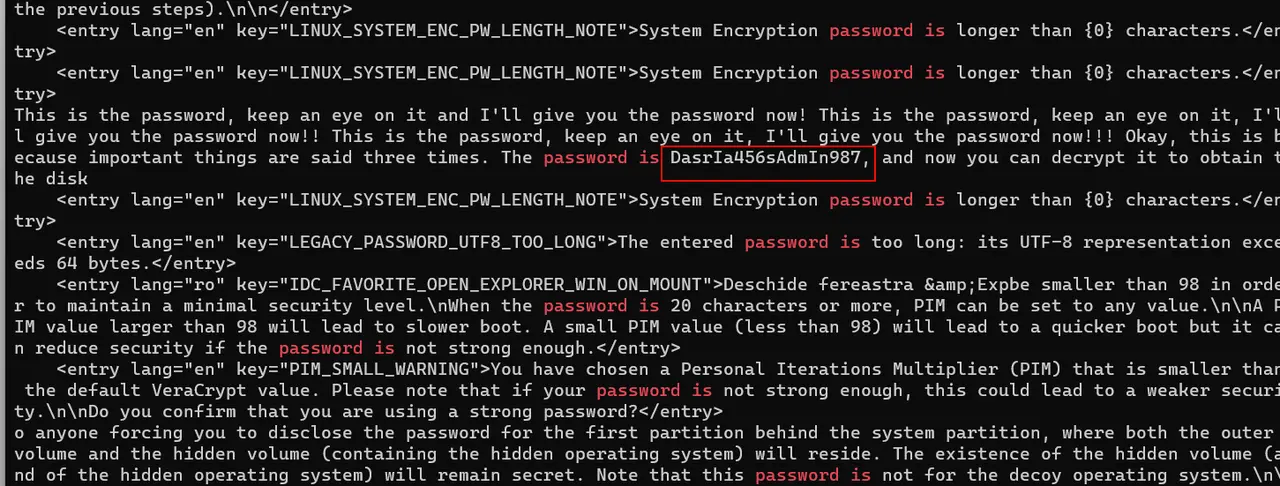
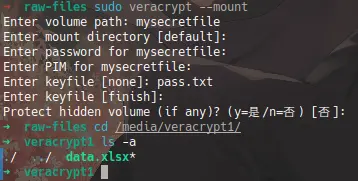
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
| from dataclasses import dataclass
from datetime import datetime, time
from hashlib import md5
from pathlib import Path
from typing import Callable, Generator, Iterable, TypeVar, cast
T = TypeVar("T")
DT = TypeVar("DT")
@dataclass
class Action:
id: int
name: str
time: datetime
statement: str
@dataclass
class User:
id: int
name: str
password: str
group: int
@dataclass
class Group:
id: int
name: str
allowed_action: list[str]
tables: list[int]
@dataclass
class Table:
id: int
name: str
allowed_range: list[tuple[time, time]]
def is_allowed(self, t: time) -> bool:
for r in self.allowed_range:
if r[0] <= t <= r[1]:
return True
return False
def extract_action_name_unchecked(statement: str) -> str:
return statement.split()[0]
def extract_target_table_unchecked(statement: str) -> str:
it = iter(statement.split())
for word in it:
if word.upper() in ["FROM", "INTO", "UPDATE"]:
break
return next(it)
def extract_csv_items(line: str) -> Generator[str, None, None]:
assert "\n" not in line and "\r" not in line, "newline char is not allowed in line."
cur = ""
quote = False
for c in line:
if not quote and c == ",":
yield cur
cur = ""
elif c == "\"":
quote = not quote
else:
cur += c
assert not quote, "quote has not closed."
yield cur
def read_actionlog(data: str) -> Generator[Action, None, None]:
for line in data.splitlines()[1:]:
items = list(extract_csv_items(line))
yield Action(
int(items[0]),
items[1],
datetime.strptime(items[2], "%Y/%m/%d %H:%M:%S"),
items[3],
)
def read_groups(data: str) -> Generator[Group, None, None]:
for line in data.splitlines()[1:]:
items = list(extract_csv_items(line))
yield Group(
int(items[0]),
items[1],
items[2].split(","),
list(map(int, items[3].split(","))),
)
def read_users(data: str) -> Generator[User, None, None]:
for line in data.splitlines()[1:]:
items = list(extract_csv_items(line))
yield User(
int(items[0]),
items[1],
items[2],
int(items[3]),
)
def read_tables(data: str) -> Generator[Table, None, None]:
for line in data.splitlines()[1:]:
items = list(extract_csv_items(line))
yield Table(
int(items[0]),
items[1],
[
cast(
tuple[time, time],
tuple(datetime.strptime(t, "%H:%M:%S").time() for t in r.split("~"))
)
for r in items[2].split(",")
],
)
def first(iterable: Iterable[T], cond: Callable[[T], bool], default: DT = None) -> T | DT:
for item in iterable:
if cond(item):
return item
return default
load_from = Path("/path/to/easy_tables附件/")
with open(load_from / "users.csv") as fp:
users = list(read_users(fp.read()))
with open(load_from / "tables.csv") as fp:
tables = list(read_tables(fp.read()))
with open(load_from / "permissions.csv") as fp:
groups = list(read_groups(fp.read()))
with open(load_from / "actionlog.csv") as fp:
actions = list(read_actionlog(fp.read()))
exps = list[tuple[int, int, int, int]]()
for action in actions:
user = first(users, lambda it: it.name == action.name)
if not user:
exps.append((0, 0, 0, action.id))
continue
action_name = extract_action_name_unchecked(action.statement)
table_name = extract_target_table_unchecked(action.statement)
group = first(groups, lambda it: it.id == user.group)
table = first(tables, lambda it: it.name == table_name)
assert group and table, "group and table is not allowed to be None."
if (
table.id not in group.tables or
action_name not in group.allowed_action or
not table.is_allowed(action.time.time())
):
exps.append((user.id, group.id, table.id, action.id))
exps.sort()
result = ",".join(("_".join(map(str, exp)) for exp in exps))
print(result)
print(md5(result.encode()).hexdigest())
|